March Madness Forecasts: FiveThirtyEight vs. Betting Markets
WARNING: SMALL SAMPLE SIZE AND BORING RESULT

I previously wrote a post about sports betting markets, where I compared the accuracy of betting market odds and forecasts from FiveThirtyEight on predicting game outcomes for the NBA (basketball), NFL (football), and MLB (baseball). Overall, the betting markets tended to slightly outperform FiveThirtyEight across all three sports. This result was consistent with the efficient market hypothesis. However, I cautioned that we shouldn’t draw any definitive conclusions, but rather we should update our beliefs in favor of sports betting markets being efficient, while also collecting and analyzing more data to see if we keep getting the same results.
Last month I decided to try to collect some more data on this question, specifically from the March Madness college basketball tournament. Unfortunately I’m also completely swamped lately (trying to finish up my dissertation this semester), so I didn’t end up recording data on all of the games, only 16 of them. Sorry about that! This is a much smaller dataset than the previous post, which included data on thousands of games over 5 years and for 3 different sports. At the same time, it has an advantage that the previous post didn’t have: I collected the data myself, so I was able to ensure that the forecasts for each game were recorded at the same time for both the betting market and FiveThirtyEight, allowing for a fair apples-to-apples comparison between the two.
Anyway I’m still going to report the results because 1.) some new data is better than no new data, and 2.) based on these results I want to put a hypothesis on the table to test with future datasets, including hopefully a similar analysis on the NBA playoffs that are coming up.
Here’s the data I collected:

Methodology Note: Betting odds data is from FanDuel. In my previous post I had much larger datasets, but a disadvantage was that I was downloading them from other sources and didn’t know the exact time they were recorded, so it wasn’t a completely 100% apples-to-apples comparison. For the dataset in this post, I recorded the data myself by actually going to the websites (FanDuel and FiveThirtyEight), checking the odds, and manually typing them into a spreadsheet, while also documenting this on video (I’ll upload the video to Youtube probably this weekend). So, this analysis is an apples-to-apples comparison, since I was able to ensure that the forecasts for both were recorded at the same time, for the same events being predicted.
Here are the resulting Brier scores (remember, lower is better for Brier scores, and a perfect score is 0):
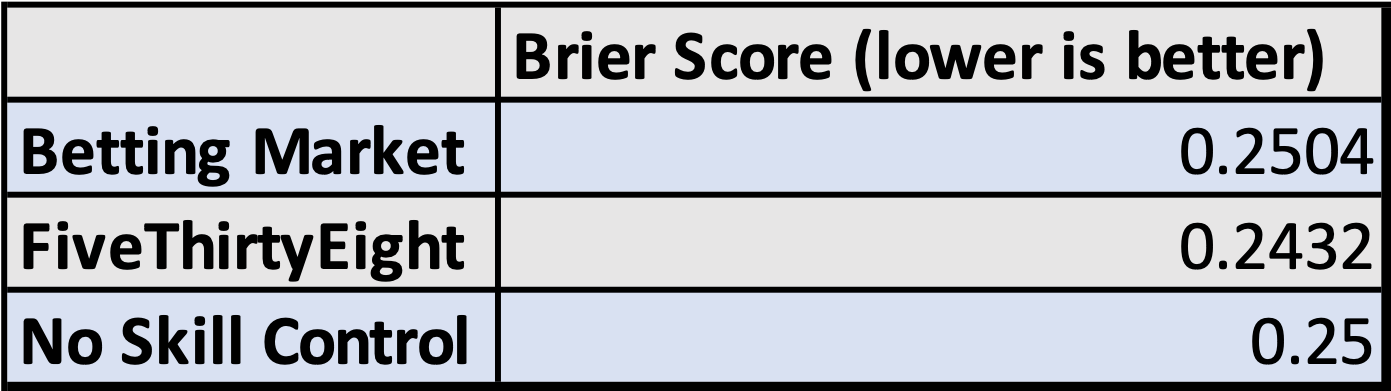
So on these 16 games (again, a small and incomplete sample), FiveThirtyEight very slightly outperformed the betting market odds, but both did about the same as the control (which simply forecast 0.5 every time).
“Mike this is a boring result, why the heck are you even making this post?”
I agree, this is a boring result! And not only that, but it’s a boring result that’s very slightly in the opposite direction of my hypothesis and a previous result that I got on a much larger dataset (that betting markets would outperform experts due to the Efficient Market Hypothesis). So yeah, from my standpoint this result is both boring and also slightly inconvenient.
The reason I’m writing this post is that it’s important to publish the boring and inconvenient results! If people only publish the exciting results that support their hypotheses, that skews the distribution of reported data. This type of publication bias is called the “filedrawer effect,” and is one of the causes behind the ongoing replication crisis in academia.
Lately I’ve been thinking that one of the most important things in science is just the non-glamorous collection and reporting of data, with the goal of contributing to a large, accurate distribution that you can use to say something about the thing you’re studying. This is going to be one of the goals of this blog — to simply collect forecast data, evaluate it for accuracy, and report the results, with the goal of producing correct information about forecasting and prediction market performance, whether that information is exciting or not.
Another reason I’m making this post is that I want to put a hypothesis on the table to test with future analyses. Hypothesis: both betting markets and expert forecasters like Nate Silver / FiveThirtyEight will tend to have worse accuracy on playoffs and tournaments compared to regular season sports games.
At first I was surprised by how badly both the betting markets and FiveThirtyEight did in this small dataset that I collected — they performed about as well as the control of simply forecasting 0.5 probability every time. This is substantially worse than their performance in my previous post, looking at mostly regular season games. But after thinking about it, this makes sense. In regular season games, you often have a matchup between a good team and a bad team, and it’s easier to predict the outcome. But in tournaments and playoffs, all of the teams are pretty good because you need to already be one of the best to make it into the tournament/playoffs. So that probably makes the forecasting harder, since there aren’t as many lopsided matchups.
Anyway this is just a hypothesis I’m putting on the table. I’d like to do a similar analysis in the NBA playoffs coming up in a couple weeks to see if I get similar results with those.
Thanks for reading!
This is great Mike! Thank you for putting in the data collection work to produce something interesting! For what it's worth, I usually bias pretty heavily toward prediction markets over 538. In the Good Judgment Open question below, tracking the implied probabilities of the betting markets fairly closely over the season gave me a brier score of -0.043 while a fellow forecaster (who is also a very good) who tracked the 538 numbers came back with a brier score of almost 0.25. As you can gather from our relative brier scores, the crowd was also closer to the betting markets than to 538 for this question. A lot of times, in other sports questions, it seems like 538 has been fairly close to prediction markets, but when they've disagreed, as per your intuition regarding EMH (which I'm convinced is at least weakly true), I've deferred to the betting markets. It will be great to see what you come up with and whether your initial hypothesis ultimately prevails. I suspect it will, but it will be great to see the empirical validation (or disconfirmation).
Here's the link: https://www.gjopen.com/leaderboards/questions/2179-which-team-will-win-the-2022-nba-finals?focused_on_id=87897
Very interesting!