Calibration of Sports Betting Markets
More Evidence from the Original Prediction Markets

Introduction
This is a continuation of a previous analysis I did using some data from sports betting markets. I’m not a huge sports person, but I’m interested in prediction markets and my idea was that maybe we can learn about prediction markets by analyzing sports betting markets. After all, they’re based on the same fundamental principles as political prediction markets (like PredictIt and Kalshi), but they’ve been around much longer, are less controversial, more legal, and have tons of publicly available data.
The previous analysis was about comparing sports betting market implied probabilities to Nate Silver’s forecasts. In that post, I only included Brier scores, since I think that’s the best metric to use for forecast comparisons (I’m open to being convinced to switch to log-odds, but have not been persuaded yet). But I wish I had included regular calibration plots too, since those are more intuitive for people who want to get a sense of how accurate forecasts are.
Anyway, this post has the calibration plots and tables for the same sports betting datasets I analyzed in the previous post. I’m partly posting this because I think some of my subscribers might be interested to see them, and I’m also partly posting it for myself to use as a reference in future writing. As I mentioned before, there isn’t a lot of publicly available data yet on political / current-event prediction markets, so when advocating in favor of prediction markets I think it can be useful to show how well calibrated sports betting markets are as a general proof of concept.
Very Short Explanation of Calibration Plots: Let’s say that I predict a 40% chance of rain tomorrow, and then it ends up raining. Does that mean that I got it wrong? Well, no… 40% isn’t zero. Things that have 40% probability happen sometimes. But I didn’t get it right either. For a single probabilistic forecast, you can never really say if it was right or wrong, unless you forecast something with 0% or 100% chance.1
But with a large collection of predictions, we can say if someone is well-calibrated or not. Being well-calibrated means that things I forecast with about 40% chance tend to happen about 40% of the time, things I forecast with about 80% chance tend to happen about 80% of the time, and so on.
Results
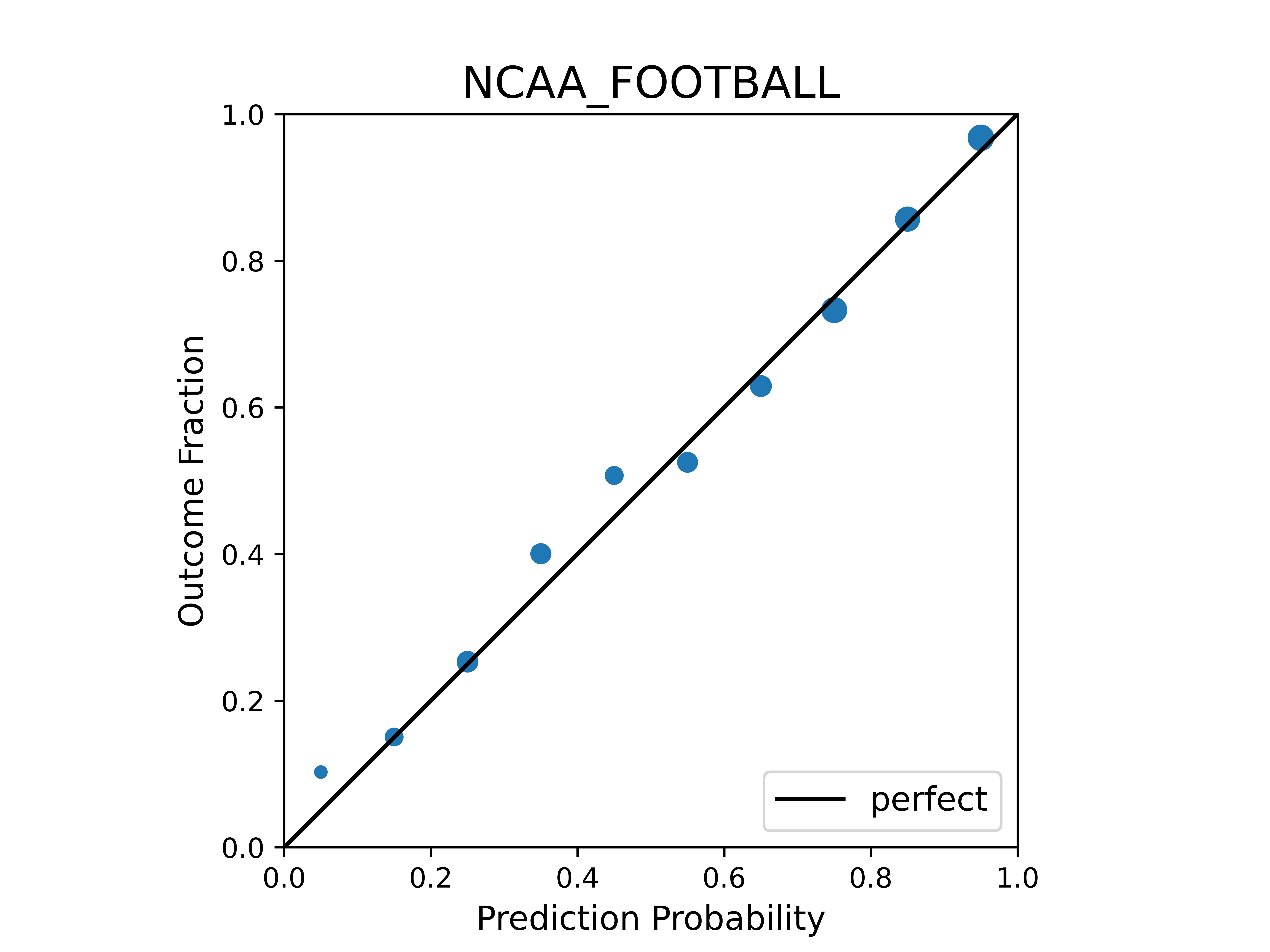
Here are the results for MLB (baseball), NFL (football), NBA (basketball), NHL (hockey), and NCAA (college football), for the 2016 - 2020 seasons. Each event is a game, and each forecast is whether the home team will win (as in the previous post), and the data is from Sportsbook Reviews Online (same source as before).
The plots are just standard calibration plots, with the outcome fraction plotted against the binned probabilities (the center of the bin, to be specific). The dots are scaled based on how many forecasts fell into that bin.
[QUICK METHODOLOGY NOTE – in sports betting, the odds are purposely set up in a way that the raw implied probabilities sum to greater than 1 (usually like 1.02 or so) [credit to u/wstewartXYZ on reddit for correcting me on this], so that the bookies are guaranteed to make money regardless of the outcome. I decided to correct this for my analysis, and normalize the implied probabilities so that they sum to 1. I think this makes sense in terms of comparing prediction accuracy, but if anyone has a good counter-argument for why I should not do this, please let me know and I’ll consider it.]
As you can see, the betting markets are remarkably well-calibrated.









Like Bloomberg News, who predicted a 100% chance of a recession last year. It didn’t happen, so if we’re going by log-odds scoring they’re now at negative infinity.
Can you make plots of how well calibrated the market is vs how long until it resolves? I.e. if the market becomes well calibrated only in the last 3 days prior to the match and previously it was only amateur creating an uncalibrated market?
This is a great analysis Mike! My intuition about whether to use Brier vs log scoring for evaluating prediction market forecasts is that it's not that important since they're both proper scoring rules which mean that, in both cases, the error minimizing strategy is to always attempt to forecast the ground truth probability. However if someone is considering gambling with their life savings (or anything where the cost for overconfidence is much higher than the cost for underconfidence), then it makes sense to use log scoring.